
この記事は5月31日に行われたNRUG メディア&エンターテイメント支部 Vol.1でユーザーLTとして登壇した様子を書き起こした記事になります。
ユーザーLT登壇者紹介

鈴木 彩人(プロダクト開発部 エンジニア(元SRE部))
2021年にメディアドゥに入社。2023年の2月まではSRE部でNew Relicの初期導入から推進までを担当し、現在は「エブリスタ」と呼ばれる小説投稿サービス(※https://everystar.jp/)の新規開発や運用改善を担当する。
メディアドゥの事業と3つのシステム課題
メディアドゥの事業について簡単に説明します。
弊社は電子書籍流通事業を展開しています。電子書籍流通事業とは、作家や出版社から受け取った書籍のデータをメディアドゥがお預かりし、電子書店や読者に配信する事業です。

トラフィックの量で言うと、月当たり数ペタバイトのデータを扱っています。
このようにトラフィックが多い電子書籍流通システムの開発、運用をしていく中で大きく3つの課題がありました。

1点目は、監視が充実していなかったこと。
主にアプリケーションの監視が不十分でした。
2点目は、障害の原因調査に時間がかかること。
障害が発生した時に、アプリとインフラどちらが起因したものなのか一目でわからない状態でした。
3点目は、パフォーマンスが可視化されていなかったこと。
書店や機能ごとのパフォーマンスの確認ができなかったり、リリース前と後でのパフォーマンスの比較ができていませんでした
これらの課題に対して、弊社がNew Relicの「APM」、「アラート」、「ダッシュボード」の3つの機能を用いて取り組みましたので、今回は活用事例として紹介させていただきます。
1点目の課題「監視が充足していない」ことについて
監視が不十分であると、その障害の発覚までに時間がかかってしまう可能性があります。そうしたことを防ぐために、少ない工数で手広く監視を構築したいという要望がありました。
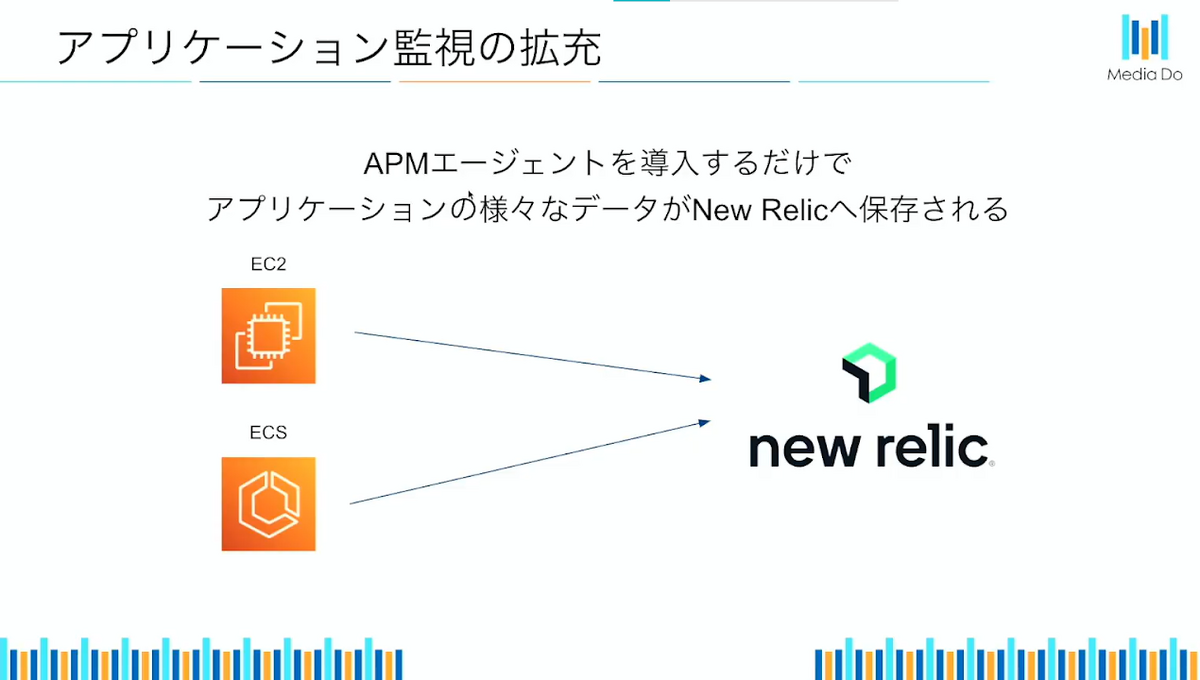
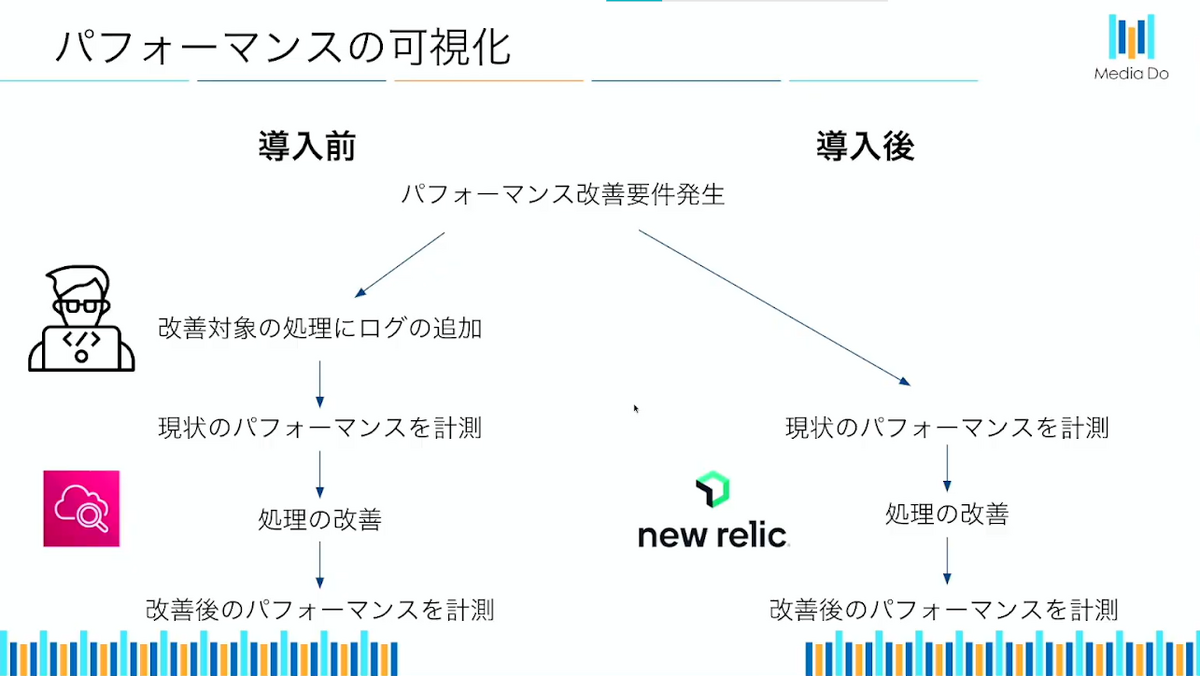
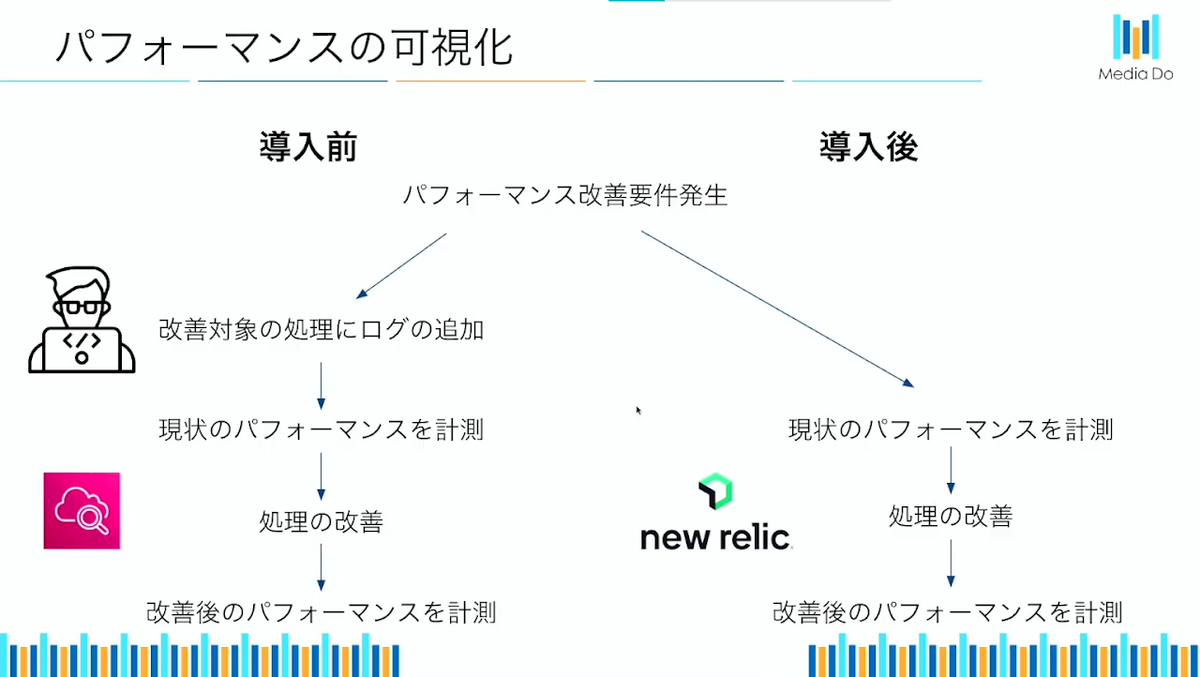
従来アプリケーションの監視を構築するためには、コード上で監視用の処理を追加する必要がありますが、New Relicではアプリケーションに手を加えることなく監視の構築ができるので、少ない工数で監視を構築することができます。
監視を作る際、まずはAPMエージェントをアプリケーションを動かしているサーバーに導入する必要がありますが、こちらのエージェントは負荷もかなり少なく、導入のスクリプトを実行するだけと簡単に導入することができます。
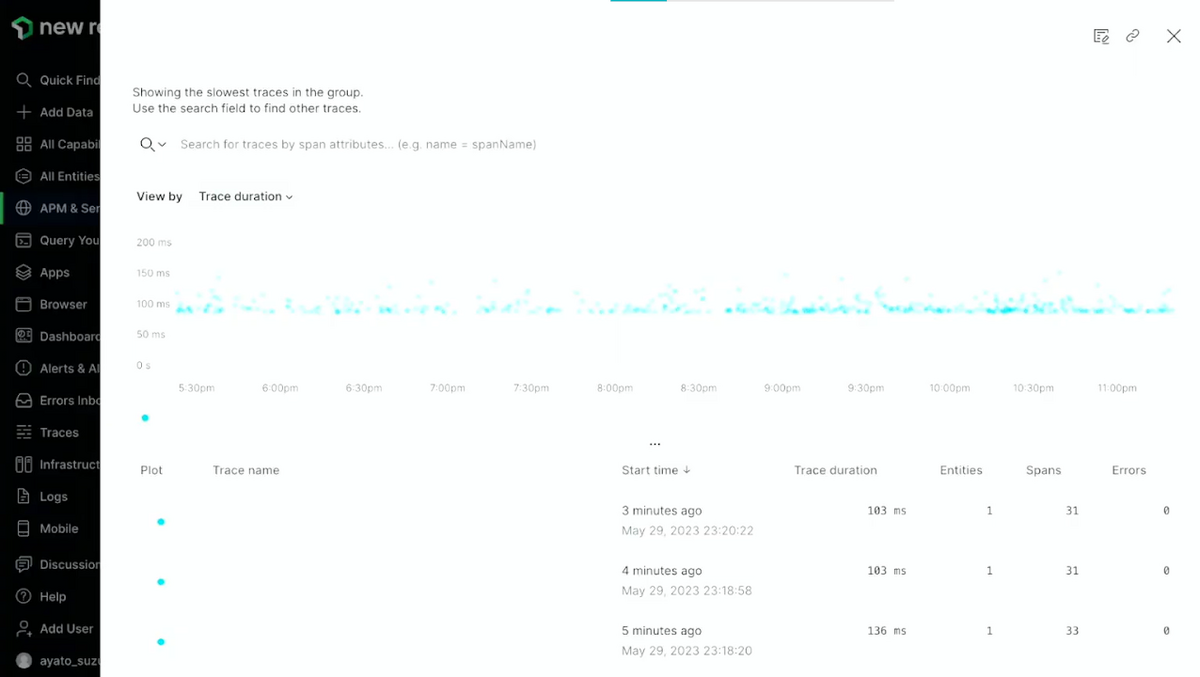
エージェントを入れるだけで、特定の処理がいつ実行されたか、どのくらいの処理時間がかかったか、エラーが何件発生しているかなどをNew Relicの画面上で確認することができます。
New Relicに保存されたモニタリングデータは、NRQL(New Relic Query Language)と呼ばれるSQLライクな言語を用いてチャートを作ったり、アラートを簡単に作ることができます。
また、New Relic社はTerraformでのプロバイダーの提供もしており、アラートをコードで管理することが可能です。
導入前は、監視構築要件が発生した時に監視用の処理をわざわざプログラムに追加した後にリリースし、CloudWatchで監視の構築をするなどしていたのですが、New Relicを導入してからはモニタリングデータがエージェントから自動で保存されるため、容易かつ柔軟に監視の構築ができるようになりました。
こうしたことから監視を構築するハードルが下がり、「監視の拡充」そして「サービスに影響が出る前に、その障害を検知して未然に防ぐ」事が可能になり、サービスの安定稼働に繋がっています。
2点目の課題「障害の原因調査に時間がかかる」点について
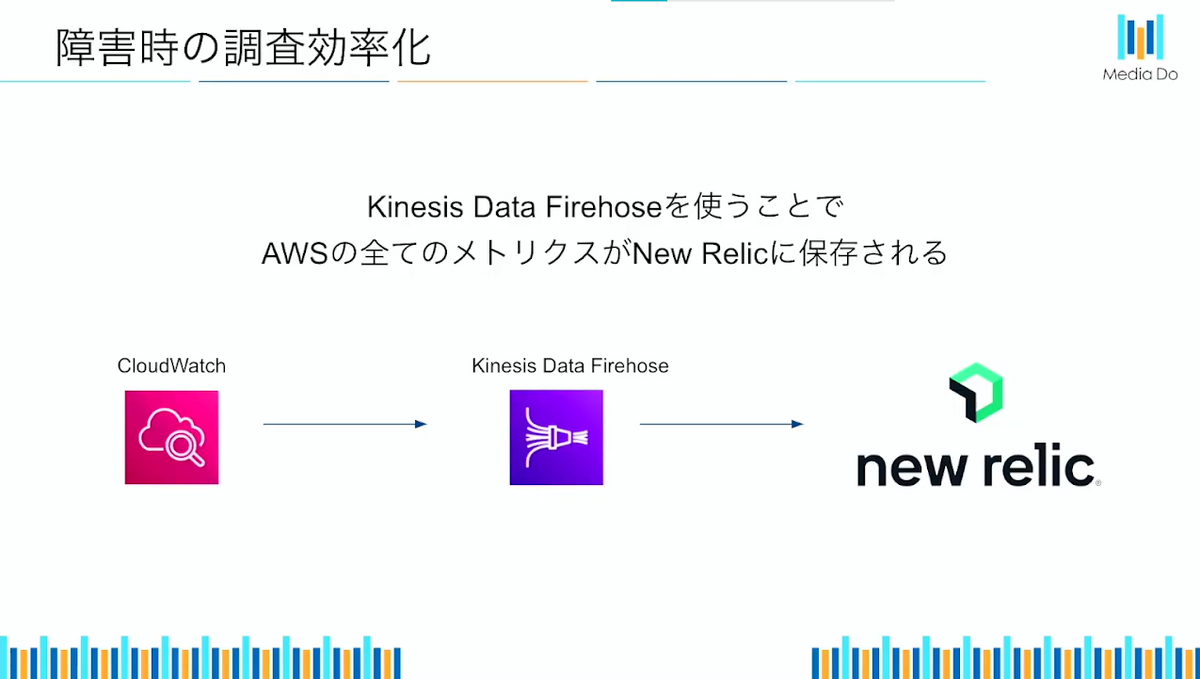
こちらはNew Relicのダッシュボードの機能を活用する事で、解決の糸口が見つかりました。
アプリケーションのモニタリングデータはエージェント経由で自動で保存され、インフラのメトリクスに関してはNew Relic社が提供してるCloudFormationを実行することで、AWSのメトリクスをすべてNew Relicに送ることが可能です。
弊社のダッシュボードの活用事例を紹介します。
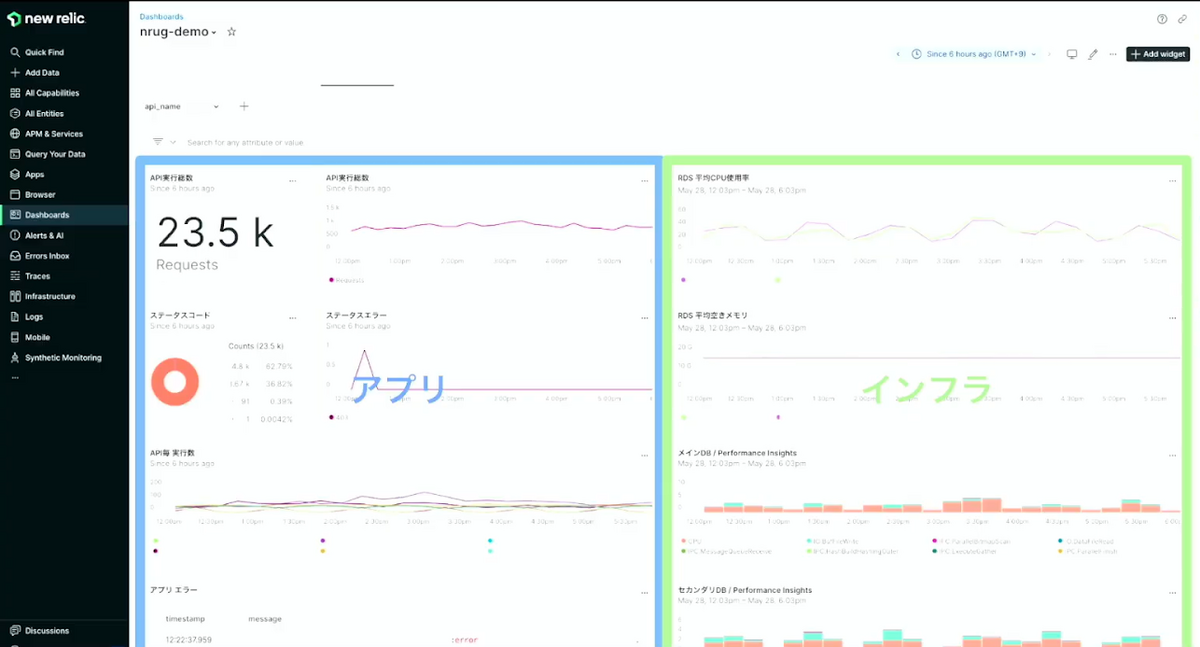
左側にアプリケーションのメトリクス、右側にインフラのメトリクスを表示しています。このようなダッシュボードをつくることで、アプリ/インフラそれぞれのメトリクスを同時に確認することができ、各表示の前後関係の比較からどちらが起因で発生した障害かということを即座に判断することができます。
New Relic導入以前は、Athenaで抽出したログから対象の書店や機能を確認後、アプリのログやインフラの負荷を確認していましたが、それらを全て1つのダッシュボードにまとめることで、エラー発生時にアプリとインフラのどちらが起因したものなのか、影響が出た書店やエラーを起こしている機能の特定といったものの調査効率化を進めることができました。
3点目の課題「パフォーマンスが可視化されていない」点です。
具体的には書店や機能ごとのパフォーマンスを確認することができず、またリリース前後でパフォーマンス比較ができていませんでした。
こちらの問題も、前述と同じダッシュボードを使うことで解決できました。
ダッシュボードのテンプレート変数という機能を使うと、チャートを動的に操作をすることができます。
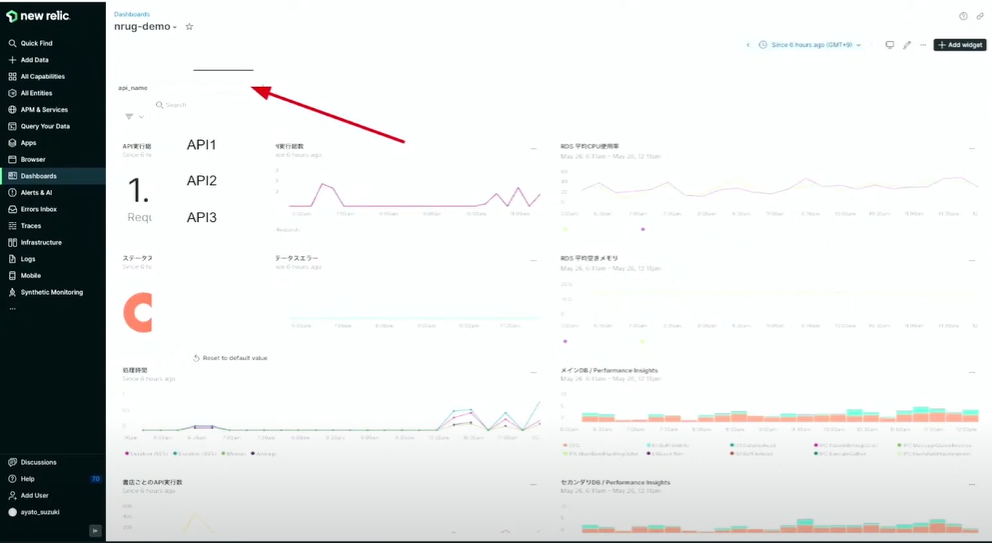
上図をご覧ください。API1を選択したら上図左側のアプリケーションのメトリクスの部分はAPI1のリクエスト数が表示され、特定の書店からのリクエスト、特定の機能でエラーが発生しているかどうかなどの状態を確認しつつ、上図右側ではインフラの負荷を確認することができます。
API1の改善が必要になった時に、リリース前後でアプリケーションのパフォーマンスを確認し、その機能が与えるインフラの負荷をダッシュボードで統合的に確認し、改善対応によるパフォーマンスの効果測定なども行えます。
またアプリケーションのパフォーマンス自体は問題ないが、インフラ側のリソースを全然使っていないといったような気づきもダッシュボードから得ることができるため、インフラ側のコスト削減のためにダウンサイジングするなどの対策を練ることもできます。
次の図は導入前と導入後の比較です。元々パフォーマンスの可視化ができていないために実装する必要のあった部分が、エージェントによって自動でNew Relicに保存されパフォーマンスが自動的に計測されることで、日々のモニタリングや計測がかなり楽になりました。
導入による成果をまとめます。
改修することなく柔軟な監視の構築が可能になり、サービスに影響が出る前に障害を検知しやすくなりました。
・2点目「障害時の調査効率化」
ダッシュボードを使うことで、アプリとインフラのどちらが起因した障害か一目で確認することが可能になりました。
・3点目「パフォーマンスの可視化」
書店や機能ごとのパフォーマンスをNew Relicで確認できるようになることで、リリース前後でパフォーマンスの比較をし、効果測定ができるようになりました。
今後の活用について
弊社では開発者全員に有償ユーザーを付与できているわけではないのですが、今回ご紹介したダッシュボードとアラートは無償ユーザーでも利用できます。
まずはNew Relicを無償ユーザーとして実証でどんどん使ってもらう中で、「これ便利じゃん」「こういうデータもっと見たいんだけど」
という声が上がったタイミングで、APMの取り入れやSQL単位で関数ごとの処理時間を確認するために、有償ユーザー数を段階的に増やしていくことを検討しています。
今後の活用としては、Service Levelsという良い機能があるので、これを使って機能ごとのSLI/SLOを策定したり、アプリケーションの脆弱性管理など、サービスの安定稼働と開発スピードの向上に向けてNew Relicをどんどん活用していきたいと思っています。