
はじめに
こんにちは。IT統括本部SRE部の栗林です。
メディアドゥは2,200社以上の出版社と150店以上の電子書店の間で電子書籍の取次を担っており、電子書籍の販売に関する情報が豊富に蓄積されています。
これらの情報を活用し、SRE部では電子書籍の売上分析用ダッシュボードを社内向けに提供しています。
この記事では、提供しているダッシュボードで発生していた課題を解決するために行ったSRE部の取り組みについて紹介します。
課題とダッシュボード
まず、課題についてですが、2点ありました。
・データの閲覧権限が部署ごとに違うため、同じようなダッシュボードを部署ごとに作成しており、ダッシュボードの数が膨大になっていた。
これらの課題を解決するために行ったことを紹介します。
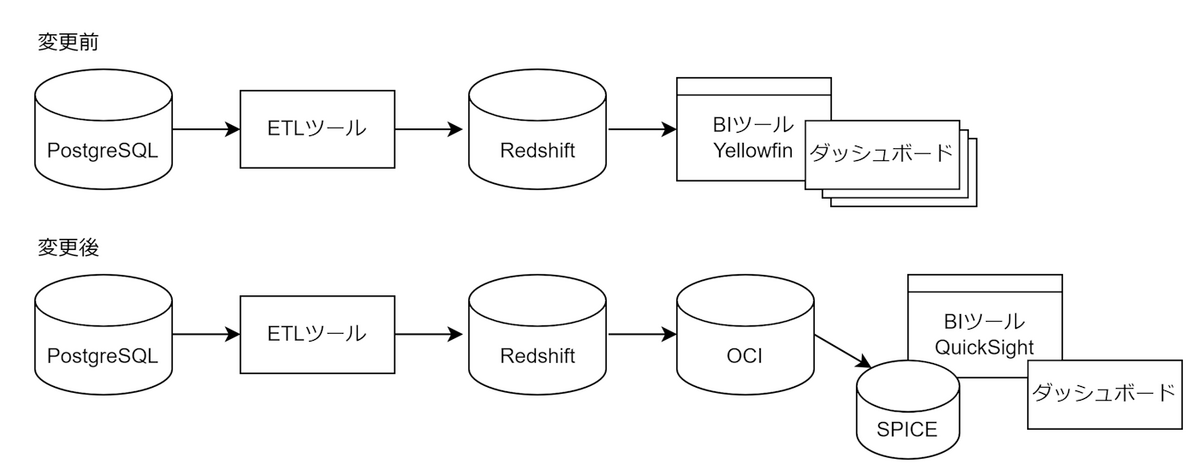
データベースとBIツールの変更
データベースをAWSのRedshiftからOCIのADWに変更し、BIツールをYellowfinからQuickSightに変更しました。
データベースはパフォーマンスへの期待と今後のデータ増加に対する対応のし易さを考慮して決定しました。
BIツールは、行レベルセキュリティ*1を使用できる点から変更しました。
BIツール変更によるデータ格納方法の変更
構成変更にあたって、BIツールから参照するデータベースへのデータ格納方法も変更しました。
変更前はPostgreSQLからETLツールを使いデータを加工し、Redshiftにデータを格納していました。
そして、格納したデータに対して直接クエリを実行し、ダッシュボードにデータを表示していました。
また、ダッシュボードは部署ごとにデータの閲覧権限に違いがあったため、さらに部署ごとにダッシュボードを作成する必要がありました。
変更後はQuickSightに変わったことによりSPICEを使用できるようになったため、SPICEにデータを載せ、表示速度の課題を解決しました。
また、QuickSightでは行レベルセキュリティも使用できるため、部署ごとのデータの閲覧権限を制御できるようになりました。
これにより、1つのダッシュボードを用意するだけで複数の部署向けに提供できるようになりました。
苦労したこと
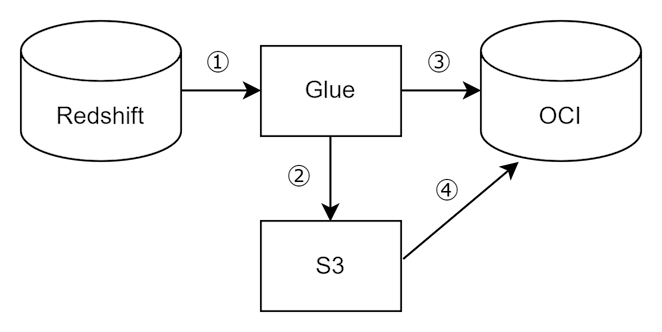
苦労したこととして、1点目にデータの格納方法があります。
RedshiftからOCIにデータを格納するとき、最初はクエリを使用していましたが、処理速度に問題がありました。
そこで、他に効果的な方法はないか探していたところ、OCIにはDBMS_COPYプロシージャが存在することを見つけました。
DBMS_COPYプロシージャはファイルを元にデータの格納を行いますが、これを用いることでクエリよりも圧倒的に速くデータの格納を可能にしました。
具体的には、①Glueを使用してRedshiftからデータを抽出し、それを②S3に格納します。
次に、③GlueからOCIに対してDBMS_COPYプロシージャを実行し、④S3に保存されたファイルをOCIに取り込みました。
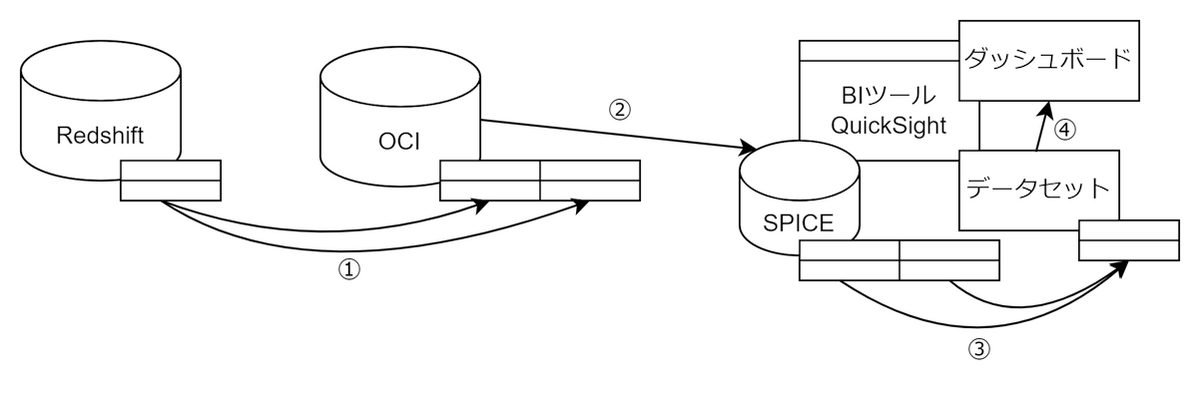
2点目は、RedshiftとOCIのカラムの最大データ長が異なる点です。
RedshiftにはOCIのデータ長より長いデータが格納されていました。
そのため、データをそのままでは格納できず、分割して格納し、取り出す際に結合する方法を行いました。
具体的には、①分割用の複数のカラムを用意し、SUBSTRING関数を使用してデータを分割し、それを用意したカラムに格納しました。
②OCIに分割して格納したデータをQuickSightのSPICEに取り込んだ後、③・④データセットで計算式を使用して結合しました。
今後の課題
今後は、ダッシュボードの拡充やデータの増加に伴い、すべてのデータをSPICEに載せることが難しくなることが予測されます。
そのため、SPICEに載せるべきデータの選別やOCIのチューニングが重要になってくると思います。
また、加工後のデータをRedshiftから取得していますが、将来的にはPostgreSQLから直接データを取得し、OCI側でデータの加工を行うことで、ETLツールとRedshiftの削減ができる可能性があるため、今後検討する必要があります。
最後に
今回はダッシュボードで発生していた課題解決のために、SRE部で実施した取り組みをご紹介しました。
課題解決にあたって新たな検討材料が見つかり、今回の課題を解決して終わりではなく、より質の高いダッシュボードの提供を進めていきたいと思います。
SRE部では、ダッシュボードに限らず様々なシステムやサービスの価値・信頼性向上を目指して、今後も課題解決・改良に取り組んでいきます。
*1:特定のユーザーがアクセスできる行をデータベース内で制御するセキュリティ機能